
Negli ultimi anni, il concetto di “emergence” nei large language models (LLM) ha acceso un intenso dibattito nella comunità scientifica. Alcuni studi sostengono che, superate certe soglie di scala (numero di parametri), i LLM sviluppino capacità nuove in modo improvviso e non lineare. Altri, invece, mettono in discussione questa interpretazione, suggerendo che il fenomeno potrebbe essere un artefatto statistico.
In questo articolo proviamo ad esplorare entrambe le prospettive, portando anche qualche esempio concreto per capire meglio.
Cosa si intende per “abilità emergenti”?
Nell'ambito dei LLM, si parla di abilità emergenti quando una capacità funzionale appare solo oltre una certa dimensione del modello e questa comparsa non può essere spiegata semplicemente con una crescita graduale delle prestazioni.
Immaginiamo di avere un modello di piccole dimensioni che non è in grado di eseguire operazioni aritmetiche con numeri interi es. 3017 + 2884.
Ora, senza cambiare il dataset di allenamento (quindi non includendo esempi di addizioni per insegnare al modello) aumentiamo man mano il numero di parametri del modello. Dopo un periodo di stallo, in cui il modello sembra non migliorare nel task, potrebbe succedere che improvvisamente inizi a risolvere correttamente una buona percentuale di addizioni.
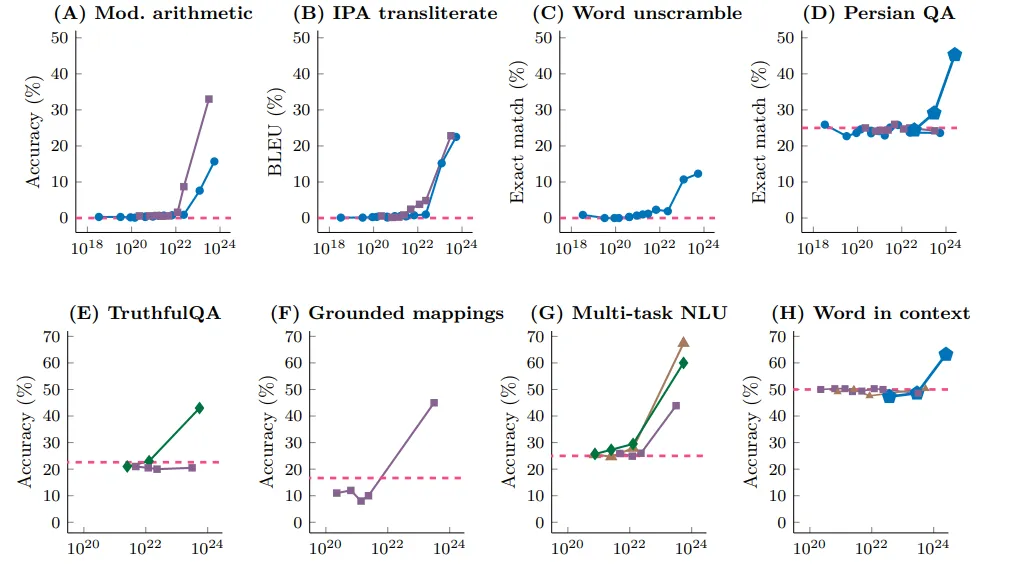
Questo è quello che effettivamente si osserva in diverse architetture di modelli e su diversi task, l’esempio delle addizioni è nel primo grafico in alto a sinistra. La linea tratteggiata rossa indica la performance di un modello che “spara a caso” il risultato. Possiamo osservare come in effetti all’inizio il modello sembra non imparare nulla, e ad una scala precisa migliora rapidamente le performance.
Secondo gli autori di “Emergent abilities of LLMs” l’emergere di queste abilità potrebbe riflettere dinamiche simili a quelle osservate nei sistemi fisici o biologici (transizione di fase). Questo suggerirebbe che i modelli di linguaggio non si comportano solo come un aggregatore di dati e parametri, ma che mostrino abilità “inaspettate” una volta superata una soglia critica nel numero dei parametri.
Dopo un primo periodo di grande fermento, in cui sembrava accertato che i modelli potessero effettivamente acquisire nuove abilità arrivano le prime critiche. In particolare nel paper "Are Emergent Abilities of Large Language Models a Mirage?" (Schaeffer et al., 2023) gli autori hanno sollevato un’obiezione fondamentale: le presunte abilità emergenti potrebbero non essere proprietà intrinseche dei modelli, ma artefatti della metrica utilizzata per valutare le prestazioni.
Molti studi utilizzano metriche di valutazione discrete (giusto/sbagliato). Se si analizzano le prestazioni con metriche continue (ad esempio la distanza tra il numero corretto e quello indovinato), i miglioramenti risultano più graduali e privi di soglie improvvise.
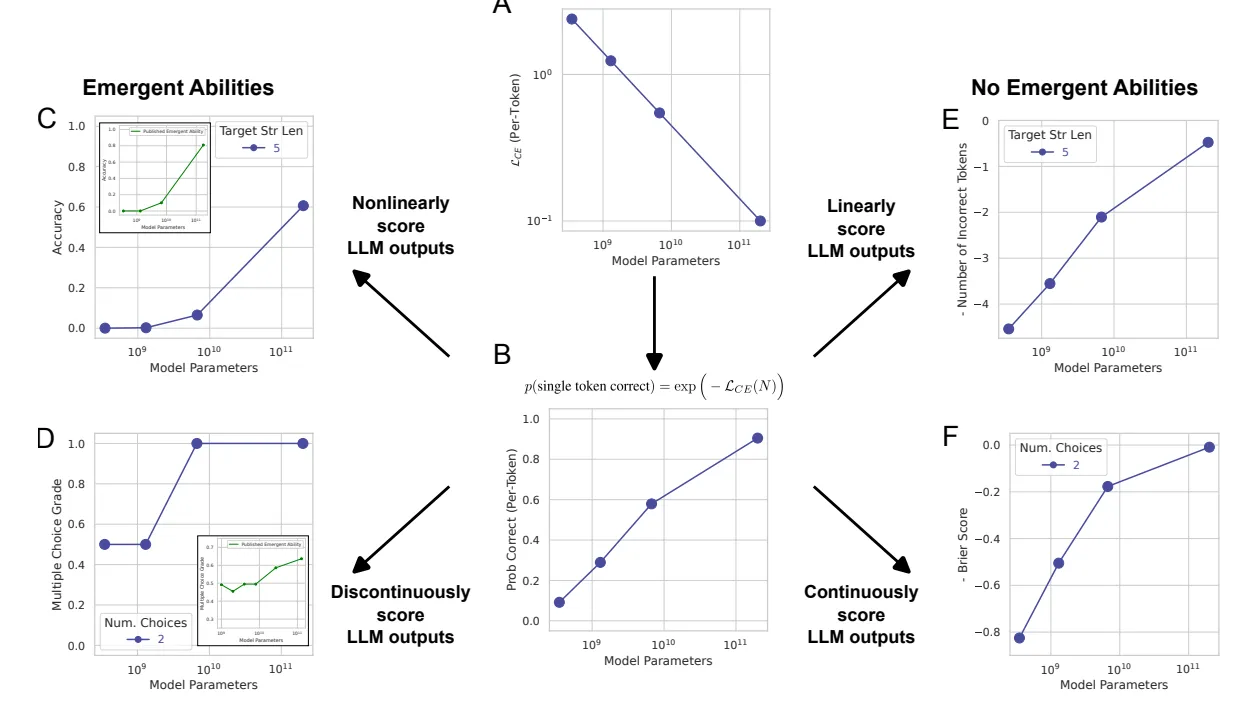
I miglioramenti improvvisi dunque potrebbero essere spiegati in molti casi da una valutazione scorretta delle performance del modello.
Torniamo all’esempio della somma di due numeri: inizialmente veniva assegnato un valore di 1 (risposta corretta) se il modello restituiva il valore esatto della somma, mentre veniva assegnato 0 (risposta sbagliata) in ogni altro caso. I LLM però sono allenati imparando a prevedere correttamente un token alla volta.
Il modello riceve come prompt: “2025 + 3333”, immaginiamo che il risultato venga generato una cifra (token) alla volta: 5,3,5 e infine 8.
Se anche il nostro modello ha una probabilità molto alta di azzeccare la prossima cifra (ad esempio il 98%) quando comporrà il numero con più cifre la probabilità di commettere un errore aumenta con il numero di cifre coinvolte. Con quattro cifre da 98% si scende al 92% di risultati corretti. Se il modello anziché essere preciso al 98% per ogni cifra lo fosse al 60%, il risultato sarebbe corretto solo nel 13% dei casi.
Ecco che quindi anche se c’è un aumento graduale nelle performance per ogni singola cifra questo si riflette “improvvisamente” sul numero intero solo quando il modello supera una certa performance di soglia per ogni singola cifra. Il paper citato sopra in particolare propone di utilizzare metriche che valutino proprio questo aumento di performance sulla singola cifra, per evitare che il comportamento sul numero intero risulti inaspettato o “emergente”.
Dove si colloca oggi il dibattito?
Dopo il paper di Schaeffer et al. il dibattito continua ad essere acceso: in parte è stata rivista la definizione di proprietà emergenti, che sono diventate proprietà per le quali l'aumento delle performance è più che lineare e non più improvviso. In altri casi si contesta l’utilizzo di metriche continue per valutare task che effettivamente hanno una natura discreta, ad esempio domande a risposta multipla.
Particolare attenzione viene recentemente dedicata anche al fenomeno del “in-context learning” cioè la capacità di eseguire nuovi task, per cui modelli LLM non sono stati allenati, solo specificando a parole il task e fornendo alcuni esempi di risultati attesi. Questo fenomeno sembra in parte legato agli studi già menzionati sulle proprietà emergenti, anche se richiede maggiore approfondimento.
Dunque tuttora il dibattito prosegue, non è ancora chiaro se queste proprietà effettivamente esistano e gli entusiasmi iniziali si sono un po’ raffreddati.
Quali sono le implicazioni?
L’emergence nei LLM non è solo una curiosità accademica. Comprendere se e come le capacità emergono ha implicazioni cruciali per:
la progettazione di modelli sempre più capaci e sicuri,
la previsione dei comportamenti futuri dell’IA,
lo sviluppo di metriche di valutazione più robuste.
Pronti a trasformare le complessità dell'IA in valore reale?
In Dhiria, non ci limitiamo a seguire le tendenze in ambito IA - le analizziamo a fondo. Che si tratti di interpretare comportamenti emergenti nei large language models, proteggere i dati con tecniche di privacy-preserving machine learning, o ricavare insight da serie temporali complesse, il nostro obiettivo è trasformare la ricerca avanzata in soluzioni concrete.
Se stai cercando un partner per applicare il deep learning in modo sicuro ed efficace, specialmente in contesti regolamentati o ad alta sensibilità dei dati, possiamo aiutarti a colmare il divario tra teoria e impatto operativo.
👉 Contattaci — scrivi a info@dhiria.com per scoprire come possiamo collaborare.
