
In recent years, the concept of “emergence” in large language models (LLMs) has ignited an intense debate in the scientific community. Some studies argue that, once certain thresholds of scale (number of parameters) are exceeded, LLMs develop novel capabilities suddenly and nonlinearly. Others, however, question this interpretation, suggesting that the phenomenon might be a statistical artifact.
In this article we try to explore both perspectives, also bringing some concrete examples to better understand.
What is meant by “emergent abilities”?
In the context of LLMs, we speak of emergent abilities when a functional ability appears only beyond a certain model size and this appearance cannot be explained simply by gradual growth in performance.
Let us imagine that we have a small model size that is unable to perform arithmetic operations with integers e.g. 3017 + 2884.
Now, without changing the training dataset (thus not including examples of addition to teach the model) we gradually increase the number of model parameters. After a period of stalling, in which the model seems not to improve in the task, it might happen that it suddenly starts solving a good percentage of the additions correctly.
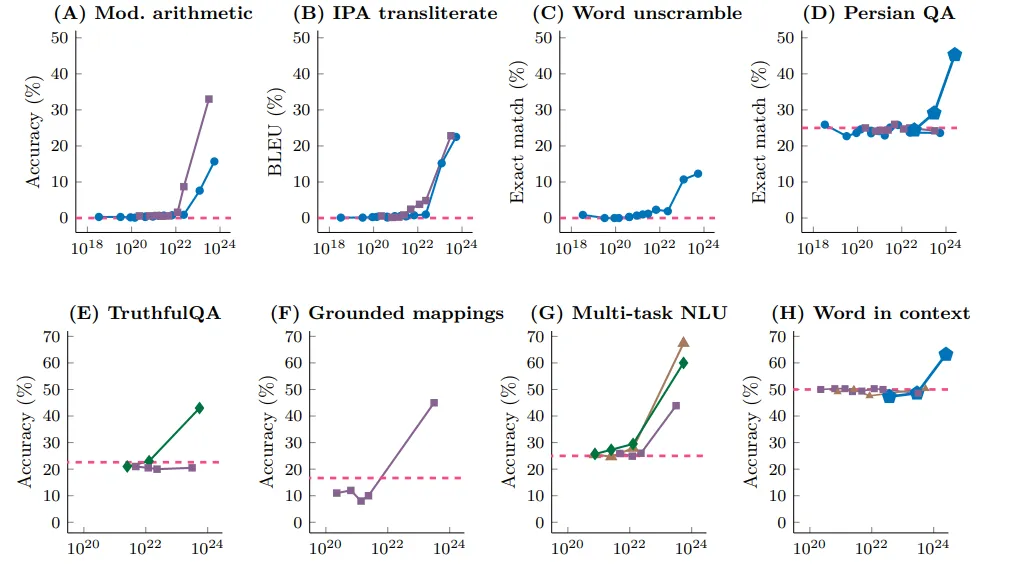
This is what is actually observed in different model architectures and on different tasks; the addition example is in the first graph in the upper left. The red dashed line indicates the performance of a model that “randomly fires” the result. We can see how in fact at first the model seems to learn nothing, and at a precise scale it rapidly improves performance.
According to the authors of “Emergent abilities of LLMs,” the emergence of these abilities could reflect dynamics similar to those observed in physical or biological systems (phase transition). This would suggest that language models not only behave as an aggregator of data and parameters, but that they exhibit “unexpected” abilities once a critical threshold in the number of parameters is crossed.
After an initial period of great excitement, in which it seemed established that models could indeed acquire new abilities comes the first criticism. Specifically in the paper "Are Emergent Abilities of Large Language Models a Mirage?" (Schaeffer et al., 2023) the authors raised a fundamental objection: the alleged emergent abilities might not be intrinsic properties of the models, but artifacts of the metrics used to evaluate performance.
Many studies use discrete evaluation metrics (right/wrong). If performance is analyzed with continuous metrics (e.g., distance between right and guessed numbers), improvements are more gradual and lack sudden thresholds.
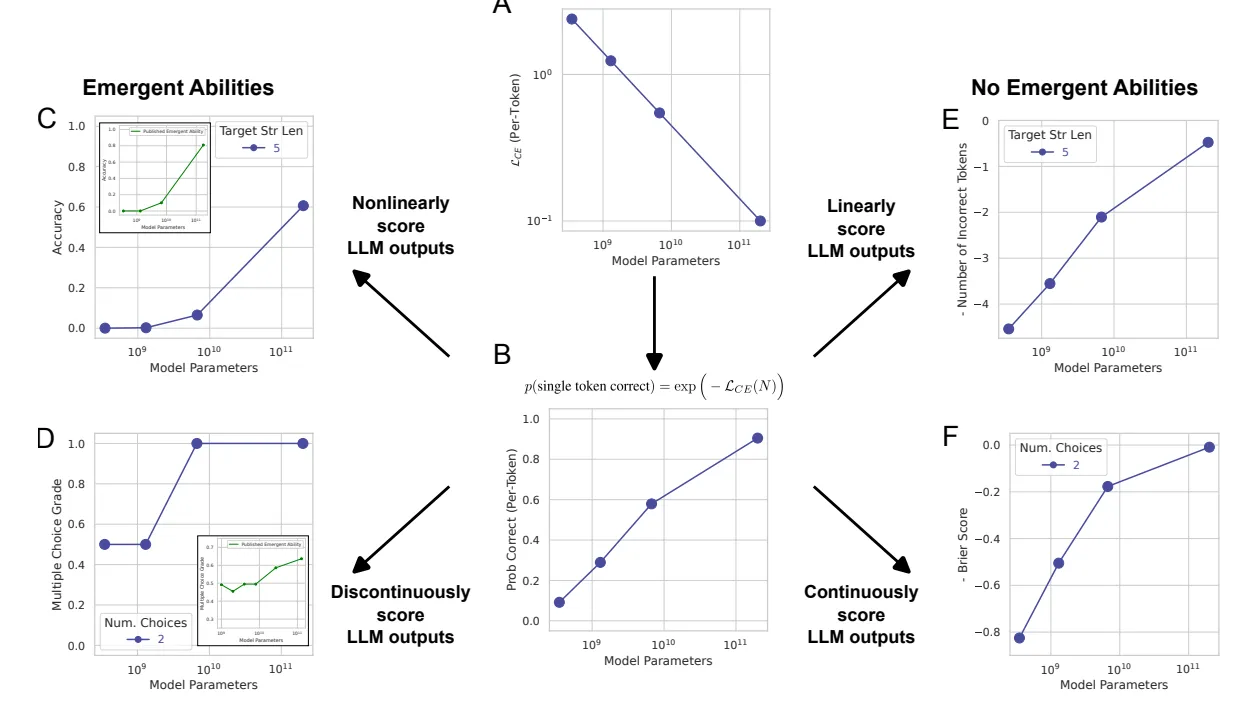
The sudden improvements therefore could be explained in many cases by an incorrect evaluation of the model's performance.
Let us return to the example of the sum of two numbers: initially a value of 1 (correct answer) was assigned if the model returned the exact value of the sum, while it was assigned 0 (wrong answer) in every other case. LLMs, however, are trained by learning to correctly predict one token at a time.
The model receives as a prompt: “2025 + 3333,” we imagine that the result is generated one digit (token) at a time: 5,3,5 and finally 8.
If our model also has a very high probability of getting the next digit right (say 98%) when it dials the multi-digit number the probability of making a mistake increases with the number of digits involved. With four digits of 98% it drops to 92% correct results. If the model instead of being 98% accurate for each digit was 60% accurate, the result would be correct in only 13% of cases.
Here then even if there is a gradual increase in performance for each digit this is “suddenly” reflected on the whole number only when the model exceeds a certain threshold performance for each digit. The paper cited above in particular proposes to use metrics that evaluate precisely this increase in performance on the single digit, to avoid unexpected or “emergent” behavior on the whole number.
Where does the debate stand today?
Since the paper by Schaeffer et al. the debate continues to be heated: in part, the definition of emergent properties has been revised to properties for which the increase in performance is more than linear and no longer sudden. In other cases, the use of continuous metrics to evaluate tasks that are actually discrete in nature, such as multiple-choice questions, is being challenged.
Special attention is also being paid recently to the phenomenon of “in-context learning” i.e., the ability to perform new tasks, for which LLM models have not been trained, only by specifying in words the task and giving some examples of expected results. This phenomenon seems partly related to the already mentioned studies on emergent properties, although it requires more investigation.
So still the debate continues, it is still unclear whether these properties actually exist, and initial enthusiasm has cooled somewhat.
What are the implications?
Emergence in LLMs is not just an academic curiosity. Understanding whether and how capabilities emerge has crucial implications for:
the design of increasingly capable and secure models,
the prediction of future AI behavior,
the development of more robust evaluation metrics.
Ready to unlock real value from complex AI phenomena?
At Dhiria, we don’t just follow AI trends — we interrogate them. Whether it's understanding emergent behavior in large language models, securing sensitive data through privacy-preserving techniques, or extracting insights from intricate time-series patterns, our team transforms advanced research into practical solutions.
If you’re exploring how to harness the power of deep learning safely and effectively, especially in regulated or data-sensitive environments, we can help you bridge the gap between theory and impact.
👉 Let’s talk — reach out to us at info@dhiria.com to explore how we can collaborate.
