
Until a few years ago, the world of Machine Learning was quite diverse: the underlying idea, also supported by a debated theorem in statistical learning theory (the No Free Lunch theorem), was that different models could excel at different tasks. Each class of algorithms, with its own specific characteristics, could be particularly suited to solving one type of problem but less effective for others.
With the comeback of neural networks, especially thanks to convolutional networks, attention began to focus on specific classes of models. Since neural networks demonstrated good performance across many different problem types, thanks to their ability to approximate any function (the Universal Approximation Theorem), they soon became the center of attention.
More recently, with the rise of LLMs (Large Language Models), we've seen something similar: there’s a widespread belief that they can do everything, particularly among those less familiar with the broader world of ML algorithms.
But are LLMs really better than every other model?
The answer is no, at least not when they are used in isolation. To understand why, let’s quickly summarize how an LLM works: to train a model, we need to feed it a large number of word sequences (text) as input and evaluate the output word sequences. If the output is indeed what we want given the input, it means the model is working well. For example, ChatGPT is designed to answer user questions, so the output must be a response to the input query.
Here we arrive at a key point: models like this work on sequences (of words), which is why they can do many interesting things with sequential data. But not all problems can be effectively represented as a sequence! Imagine trying to give someone a map of your city: would you rather explain in words where all the streets are, or simply draw the map and hand it over? A text-based LLM is not designed to process and represent data that would best be conveyed through a drawing, because a map isn’t a sequential object, it more closely resembles a mathematical structure called a graph.
You can test this yourself: just open ChatGPT in one of its offline versions (like GPT-4 without browsing), then open a map of your city and pick two points to plot a walking route between. Ask ChatGPT to give you walking directions (without using public transport), and check how many mistakes it makes.
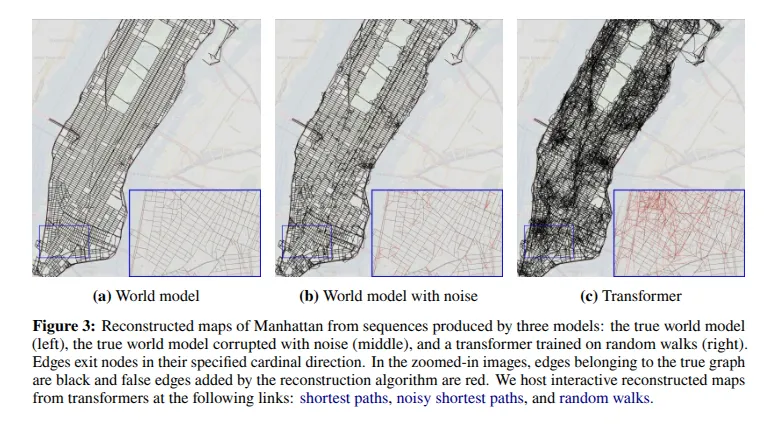
Researchers from Harvard and MIT did a similar experiment on a map of Manhattan, asking an LLM to plot routes after training it on the layout of the map using many sequences of streets (i.e., trying to explain the map in words).
Interactive version of the map: https://manhattan-reconstruction-noisy.netlify.app/
On the left is the real map, and on the right is the map reconstructed by an LLM, you can immediately spot the differences.
The representation generated by the LLM includes many non-existent connections between city points.
In the experiments, the researchers highlighted the problems caused by this flawed representation: the model could return a fairly accurate route between two points, but as soon as you asked to slightly modify the path (e.g., due to a closed road), the model produced the infamous hallucinations i.e., incorrect results. You can visually understand why the LLM returns unexpected results: the map it builds only partially resembles the real one, so as long as you're on roads the model is confident about, the results are correct, but any small change causes it to explore incorrect connections.
In practice, a classic optimization algorithm, which operates on a real map turned into a graph, will vastly outperform an LLM in connecting two points on a map.
This example applies to many other problems (e.g., logic problems) where a sequential representation is not ideal. Such problems might be better represented with graphs, functions, or multidimensional geometric spaces (like images).
LLMs undoubtedly offer a wide range of capabilities today, but it’s important to understand that they can’t excel at every task. Much research is focused on integrating various algorithms through a text-based interface to improve performance on more complex tasks (here). However, this doesn’t necessarily mean that we should rely on LLMs for every task: having a clear understanding of which models work best in which contexts is still a major advantage, especially since the text interface has its limitations, even if it could theoretically “do everything” (first and foremost, speed).
Most importantly, it’s risky to put blind trust in the world representation built by an LLM (or by any black-box model, for that matter), because unless we explicitly provide it, that representation will contain errors, even if they aren’t immediately evident from the model’s responses. These inaccuracies tend to emerge precisely in edge cases, where an accurate representation is most critical. For example, when we want to avoid roadblocks or deviate from a familiar route.
There are already LLMs trying to integrate multimodality, but they require other models to be incorporated into the ecosystem (e.g., a convolutional network), and they don’t necessarily perform better than the standalone specialized model.
For instance, if we want to classify an image, we could use a multimodal LLM—or we could just use a convolutional network, which, at a fraction of the cost, gives results that are comparable or even superior.
In short, specialized models still outperform general-purpose models like LLMs in many domains, and it’s crucial to assess which model is best suited for a given business need. The answer is not always obvious!
Ready to go beyond the hype?
At Dhiria, we believe in using the right model for the right task—not just the flashiest one. Whether you need optimized routing, logical reasoning, or privacy-preserving AI tailored to your data, our team helps you combine LLMs and specialized models to deliver robust solutions.
👉 Let’s talk about building your next AI system the smart way.
Contact us by email or through this website to explore how hybrid intelligence can solve your real-world challenges.





