
Fino a qualche anno fa il mondo del Machine Learning era molto vario: l’idea di fondo, supportata anche da un discusso teorema della teoria dell’apprendimento statistico (no free lunch theorem) era che modelli diversi potessero eccellere in task diversi. Ogni classe di algoritmi con le sue specificità infatti poteva essere particolarmente adatta a risolvere un particolare problema, ma meno a risolverne altri.
Già con il ritorno delle rete neurali, specialmente grazie alle reti convoluzionali, l’attenzione ha iniziato a concentrarsi su alcune specifiche classi di modelli. Siccome le reti neurali dimostravano buone performance su molti tipi di problemi diversi, grazie alla loro capacità di approssimare qualsiasi funzione (universal approximation theorem), sono presto passate al centro dell’attenzione.
Più recentemente con l’emergere di modelli LLM (Large Language Model) abbiamo assistito a qualcosa di simile: circola infatti la convinzione che siano in grado di fare tutto, specialmente tra chi è meno a conoscenza del vasto mondo degli algoritmi di ML.
Ma quindi i LLM sono davvero meglio di ogni altro modello?
La risposta è no, quantomeno se non integrati con altri modelli. Per capire come mai cerchiamo anzitutto di riassumere velocemente come funziona un LLM: per allenare un modello dobbiamo passare tantissime sequenze di parole (testo) in input e valutare la sequenza di parole (testo) in output. Se la sequenza di parole in output è effettivamente quello che desideriamo dato l’input vorrà dire che il modello sta funzionando bene. Ad esempio chatGPT ha come obiettivo rispondere alle domande dell’utente, quindi l’output dovrà essere una risposta alla richiesta che si trova nell’input.
Qui arriva un punto fondamentale da comprendere: modelli di questo tipo lavorano su sequenze (di parole) e sono quindi in grado di fare molte cose interessanti proprio su dati di tipo sequenziale. Ma non tutti i problemi si possono rappresentare in maniera efficace con una sequenza! Immaginate di dover dare a qualcuno una mappa della vostra città: preferireste spiegare a parole dove si trovano tutte le vie oppure fare un disegno e consegnare direttamente quello? Un LLM testuale non è progettato per elaborare e rappresentare dati che nel nostro esempio inseriremmo in un disegno, perché una mappa non è un oggetto sequenziale ma assomiglia di più ad oggetti matematici chiamati grafi.
Potete sperimentare voi stessi questa cosa: basta andare su chatgpt ed aprire una delle versioni non in grado di cercare su internet (ad esempio GPT 4), dopodiché aprite una mappa della vostra città e decidete due punti tra i quali farvi tracciare un percorso. Chiedete a chatGPT di darvi un percorso a piedi (senza usare i mezzi) tra i due punti e verificate quanti errori commette.
Alcuni ricercatori di Harvard e MIT hanno provato un esperimento simile sulla mappa del quartiere di Manhattan, chiedendo ad un LLM di tracciare percorsi dopo che avevano insegnato al modello come era fatta la mappa inserendo tante sequenze di vie (tentando cioè di spiegare a parole come è fatta la mappa).
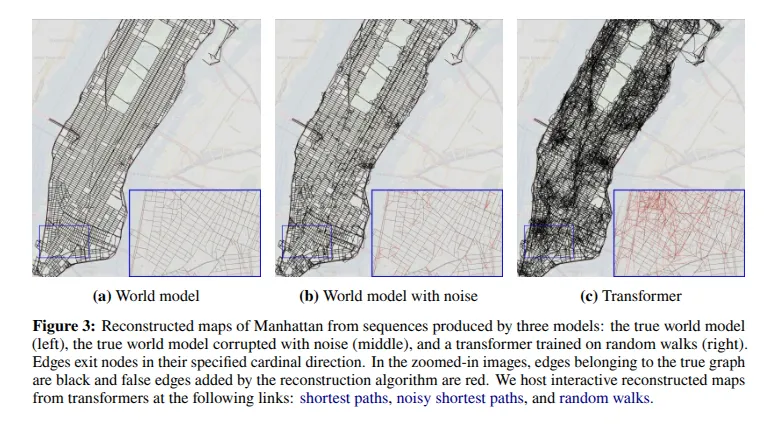
A sinistra vediamo la mappa reale, mentre a destra vediamo la mappa ricostruita da un LLM, la differenza si nota immediatamente.
La rappresentazione generata da un LLM contiene un sacco di connessioni inesistenti tra punti della città.
Negli esperimenti i ricercatori evidenziano il problema di questa rappresentazione errata: il modello è in grado di restituire con una precisione abbastanza elevata un percorso tra due punti, ma appena si chiede di modificare leggermente l’itinerario (ad esempio per la chiusura di una via) il modello restituisce le famose “allucinazioni” cioè risultati errati. Qui si vede graficamente come mai il LLM restituisce risultati inattesi: la mappa costruita dal LLM assomiglia solo in parte a quella reale, quindi fino a che percorriamo strade su cui il modello ha un’alta confidenza il risultato è corretto, ma una qualsiasi piccola modifica porta ad esplorare le connessioni errate.
In pratica un algoritmo di ottimizzazione classico, che si basa su una mappa reale trasformata in un grafo, produrrà performance molto superiori ad un LLM nel collegare due punti sulla mappa.
Così come in questo caso per molti altri problemi (es. problemi di logica) la rappresentazione sequenziale non è la più indicata, potrebbero essere problemi meglio rappresentabili con grafi, funzioni o in uno spazio geometrico a più dimensioni (es. immagini).
Sicuramente i LLM offrono oggi una grande varietà di funzioni, ma è necessario capire che non possono eccellere in ogni task. Molta ricerca infatti mira proprio ad integrare tanti algoritmi attraverso una interfaccia di tipo testuale per migliorare le performance in questi task più complicati (https://arxiv.org/abs/2305.12295). Non è però scontato che questo implichi la necessità di appoggiarsi solo ad un LLM per ogni tipo di task: avere una idea chiara di quali modelli possono funzionare bene in quale terreno è ancora un vantaggio importante, perché l’interfaccia testuale ha comunque limitazioni anche nel caso in cui potesse fare tutto (prima tra tutte la velocità di risposta).
Soprattutto è pericoloso riporre fiducia nella rappresentazione del mondo che costruisce un LLM (ma in realtà anche un qualsiasi altro modello black box), perché questa rappresentazione se non fornita direttamente da noi conterrà degli errori, anche se non si intuisce direttamente dalle risposte del modello. La non correttezza della rappresentazione potrebbe emergere proprio in quella situazione limite in cui ci servirebbe avere una rappresentazione corretta: ad esempio nel caso in cui volessimo evitare blocchi stradali o deviare dalla strada che conosciamo.
Esistono già LLM che cercano di integrare la multimodalità, ma richiedono appunto altri modelli da integrare nell’ecosistema (ad esempio una rete convoluzionale) e non necessariamente producono risultati migliori del modello aggiuntivo preso da solo.
Immaginiamo ad esempio di voler classificare una immagine, possiamo ricorrere ad un LLM multimodale oppure utilizzare direttamente una rete convoluzionale, che ad una frazione del costo consente di ottenere risultati comparabili o migliori.
Insomma in questo momento è ancora vero che un modello specifico restituisca performance superiori ad un modello generico in grado di fare tutto, è importante valutare quale modello è il più indicato a seconda delle esigenze di business. La risposta non è sempre scontata!





