
Se hai passato del tempo a utilizzare chatbot basati su Large Language Models (LLMs), probabilmente hai sperimentato la loro cosiddetta modalità di “ragionamento”. In questo contesto, il modello sembra risolvere problemi adottando un approccio più strutturato, utilizzando quella che tecnicamente è nota come chain-of-thought prompting.
Ma questi modelli ragionano davvero? O stiamo semplicemente assistendo a un riconoscimento superficiale di pattern/strutture linguistiche?
Un recente articolo di Apple, intitolato “The Illusion of Thinking”, affronta direttamente questa domanda. Gli autori propongono un quadro rigoroso per valutare scientificamente le capacità di ragionamento dei LLM.
Il contributo principale del paper è un benchmark che valuta il ragionamento su problemi con complessità modulabile, inclusi molti garantiti come fuori distribuzione rispetto ai dati di addestramento. I risultati sono sorprendenti.
Uno degli spunti più interessanti di The Illusion of Thinking è la fragilità del ragionamento dei LLM quando vengono esposti a problemi veramente nuovi. Una parte significativa della ricerca precedente che valuta le capacità di ragionamento dei LLM si basa su benchmark come GSM8K, un dataset composto da problemi di matematica a livello di scuola elementare. Questi esercizi vengono spesso utilizzati per testare il ragionamento aritmetico e la risoluzione di problemi multi-step.
Tuttavia, c’è un problema: molti di questi benchmark (o delle loro parafrasi molto simili) sono già stati visti durante l’addestramento del modello. Questo porta a quello che viene definito data contamination, ovvero una situazione in cui i dati di valutazione si sovrappongono, direttamente o indirettamente, con quelli usati in fase di training. Di conseguenza, le prestazioni del modello possono riflettere una memorizzazione o un riconoscimento superficiale dei pattern, piuttosto che un vero ragionamento.
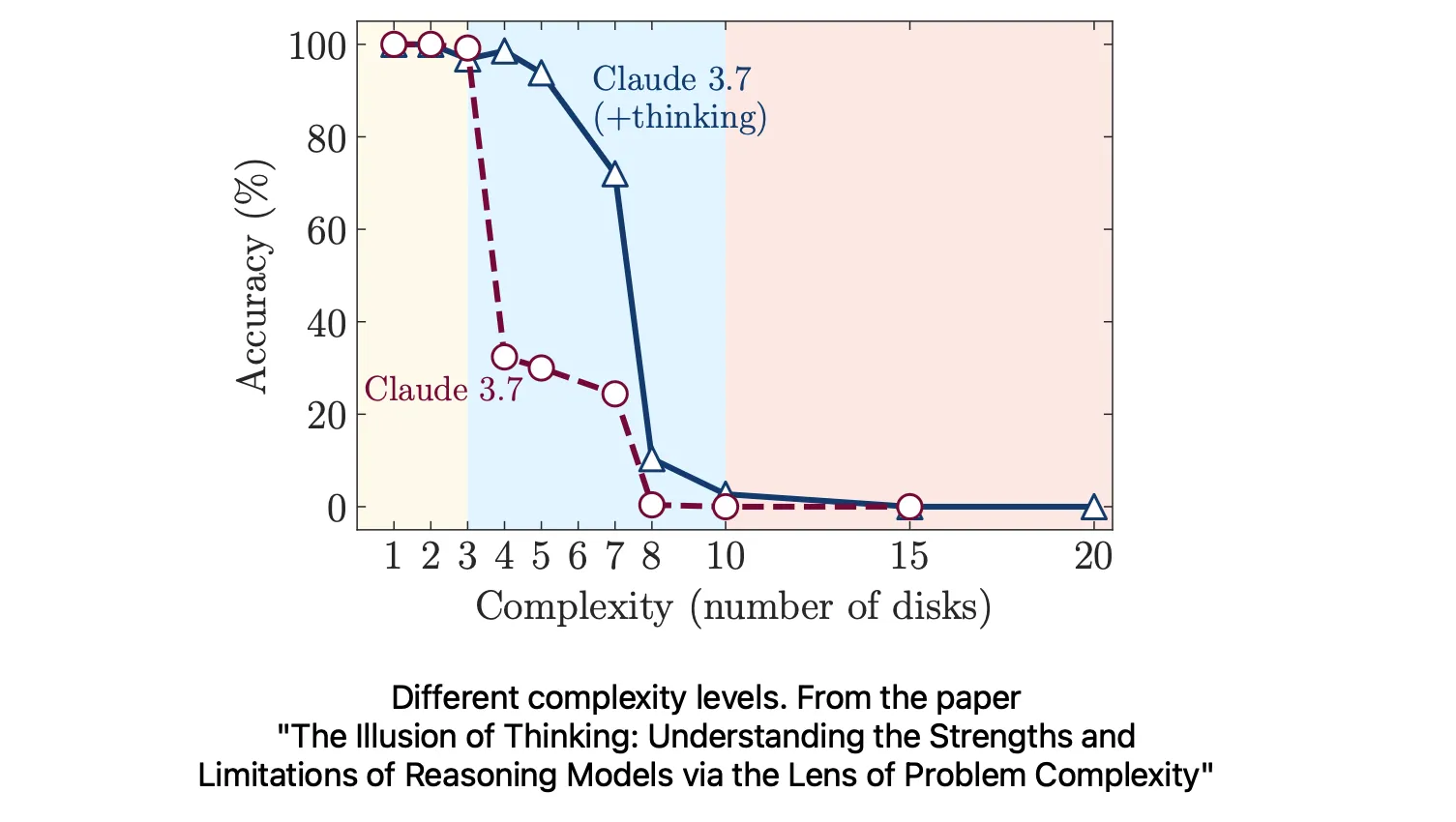
Per indagare questa dinamica, i ricercatori hanno preso in considerazione compiti con complessità modulabile, come la Torre di Hanoi, in cui il numero di dischi può essere variato per ottenere versioni più semplici o più complesse del problema. Hanno così classificato i task in tre livelli:
Bassa complessità: problemi semplici che richiedono pochi passaggi di ragionamento.
Media complessità: compiti che richiedono una pianificazione e un ragionamento moderati.
Alta complessità: sfide che richiedono un ragionamento multi-step esteso e articolato.
I risultati hanno mostrato che i LLM standard spesso superano i modelli ottimizzati per il ragionamento nei compiti a bassa complessità, probabilmente perché questi ultimi tendono a “pensare troppo”, introducendo complicazioni inutili. I modelli ottimizzati per il ragionamento si comportano meglio nelle situazioni di media complessità, dove un pensiero strutturato può davvero fare la differenza, ma entrambi i tipi di modelli falliscono completamente nei compiti ad alta complessità. Curiosamente, il calo di performance si manifesta nonostante ci siano sufficienti risorse computazionali e spazio nel token budget.
Questo degrado delle prestazioni nei task più complessi è particolarmente interessante. I modelli mostrano un “limite di scala controintuitivo”: lo sforzo di ragionamento cresce con la complessità del problema fino a un certo punto, ma poi cala bruscamente, anche se avrebbero ancora la capacità di processare output più lunghi. Ciò suggerisce che i modelli siano in grado di percepire l’aumento della difficoltà, ma manchino dei meccanismi per affrontare o pianificare efficacemente strategie adeguate nei contesti più complessi.
Il secondo contributo principale di The Illusion of Thinking dimostra che i LLM spesso falliscono nel risolvere problemi anche quando viene fornito loro l’algoritmo corretto in modo esplicito. Verrebbe naturale pensare che, se al modello si fornisce una procedura chiara e dettagliata, sotto forma di linguaggio naturale o pseudocodice, dovrebbe essere in grado di seguirla passo dopo passo e arrivare alla soluzione corretta. In fondo, eseguire una sequenza nota di operazioni dovrebbe rappresentare un test minimo di ragionamento. Ma i risultati raccontano un’altra storia.
I ricercatori hanno progettato esperimenti in cui i modelli venivano istruiti con l’intera descrizione algoritmica necessaria per risolvere una determinata classe di problemi. Nonostante questo vantaggio, i modelli spesso si discostavano dalla procedura, saltavano passaggi o addirittura allucinavano risultati intermedi. In alcuni casi, abbandonavano completamente la logica a metà strada, anche se disponevano ancora di un budget di token sufficiente per completare il task.
Questo fallimento non è attribuibile a limiti di capacità o a istruzioni poco chiare, ma piuttosto a una debolezza nell’esecuzione fedele dell’algoritmo. I modelli sono spesso in grado di ripetere l’algoritmo, ma non di applicarlo correttamente e con coerenza.
Un aspetto interessante evidenziato dagli autori è che i modelli riescono meglio in questi casi solo quando sono agentici, ovvero quando possono utilizzare strumenti esterni o eseguire codice. In questi scenari, il compito di ragionamento strutturato può essere delegato a un interprete affidabile, come ad esempio un ambiente Python. Tuttavia, il paper esclude volutamente questo tipo di approccio, concentrandosi esclusivamente su ciò che i LLM statici riescono a fare da soli, senza il supporto di strumenti esterni.
Il messaggio è chiaro: gli LLM attuali sono ancora deboli nell’esecuzione algoritmica. Non riescono a legare in modo affidabile le istruzioni alle azioni. Anche quando il “pensiero” è stato già svolto per loro, possono comunque inciampare nell’esecuzione, un’ulteriore conferma che il loro apparente ragionamento si basa spesso più sul completamento di pattern che su una reale comprensione logica.
Va notato che il team guidato da Samy Bengio ha iniziato a indagare il tema del ragionamento nei LLM già da tempo, con alcuni lavori precedenti che hanno aperto la strada al recente The Illusion of Thinking.
Uno dei fenomeni che hanno analizzato riguarda l’estrema sensibilità dei modelli alle modifiche superficiali nei problemi standard di benchmark: cambiando nomi, valori numerici o inserendo dettagli irrilevanti, l’efficacia dei LLM nel risolvere questi problemi cala drasticamente. Sorprendentemente, anche piccole variazioni, come sostituire il nome “Sophie” con “Mark”, possono provocare un crollo significativo dell’accuratezza. Questi modelli, a quanto pare, possono essere facilmente ingannati da modifiche che non alterano la logica del problema.
Questo comportamento era già stato documentato in uno studio precedente di Bengio et al., noto come GSM-symbolic. In quel lavoro, gli autori hanno dimostrato che alterare i nomi delle entità o inserire informazioni fuorvianti in problemi di matematica o logica può indurre il fallimento dei LLM, anche quando la struttura di ragionamento sottostante resta identica. La lezione fondamentale era che i modelli spesso non risolvono i problemi perché li capiscono davvero, ma perché riconoscono schemi già visti. In altre parole, il loro successo è dovuto a capacità “da pappagallo”, non a una vera astrazione o ragionamento.
Nel complesso, questi risultati mettono in discussione l’idea che gli attuali LLM possiedano abilità di ragionamento in senso significativo. Possono sembrare capaci di risolvere compiti complessi, ma spesso ci riescono solo perché quei compiti assomigliano a qualcosa che hanno già visto, non perché li abbiano realmente compresi.

Alla International Joint Conference on Neural Networks (IJCNN 2025) di Roma, dove ho avuto l’opportunità di assistere al keynote di Samy Bengio, il ricercatore ha concluso delineando una direzione promettente per i lavori futuri: il concetto di abstract thinking.
L’idea di base è semplice: durante la fase di addestramento, annotare i problemi di input con marcatori variabili astratti, ad esempio etichettando numeri o entità con simboli generici (come X, Y, N1), anziché affidarsi a descrizioni in linguaggio naturale del tipo “Sophie ha 5 mele…”. Questa piccola modifica spinge i modelli a trattare problemi simili come istanze della stessa struttura logica di base, invece di memorizzare pattern superficiali.
Questa linea di ricerca in continua evoluzione ci ricorda che, sebbene i LLM possano sembrare intelligenti, il vero ragionamento richiede molto più della sola fluidità nell’output. Richiede struttura, generalizzazione e interpretabilità.




