
Hai mai notato come certi schemi si ripetano nel tempo?
Il call center è sempre più affollato il lunedì. A gennaio ti senti più stanco. La piscina si riempie nei weekend.
Queste osservazioni sono, in piccolo, forme di previsione: noti un pattern nel passato e lo usi per intuire cosa accadrà.
In data science, questo tipo di intuizione prende il nome di time series forecasting, la capacità di usare i dati storici per stimare valori futuri. È come dire: “Se le vendite sono sempre aumentate prima di Natale, cosa mi aspetto per quest’anno?”.
Cosa sono le serie temporali
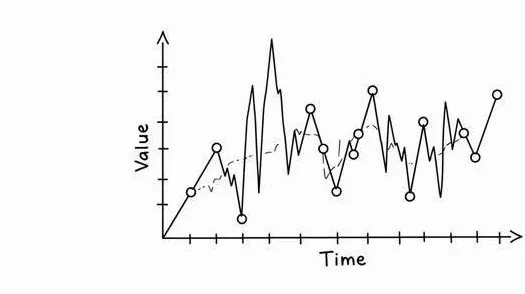
Una serie temporale è semplicemente un insieme di dati raccolti a intervalli regolari nel tempo: ogni punto rappresenta un momento preciso, ed è collegato al precedente e al successivo.
Può trattarsi dell’andamento di un titolo in borsa, delle visite giornaliere a un sito o del numero di pizze vendute in un ristorante.
L’elemento chiave è che l’ordine temporale conta: non puoi rimescolare i dati come faresti in un normale dataset, perché ogni valore dipende da quelli che lo hanno preceduto.
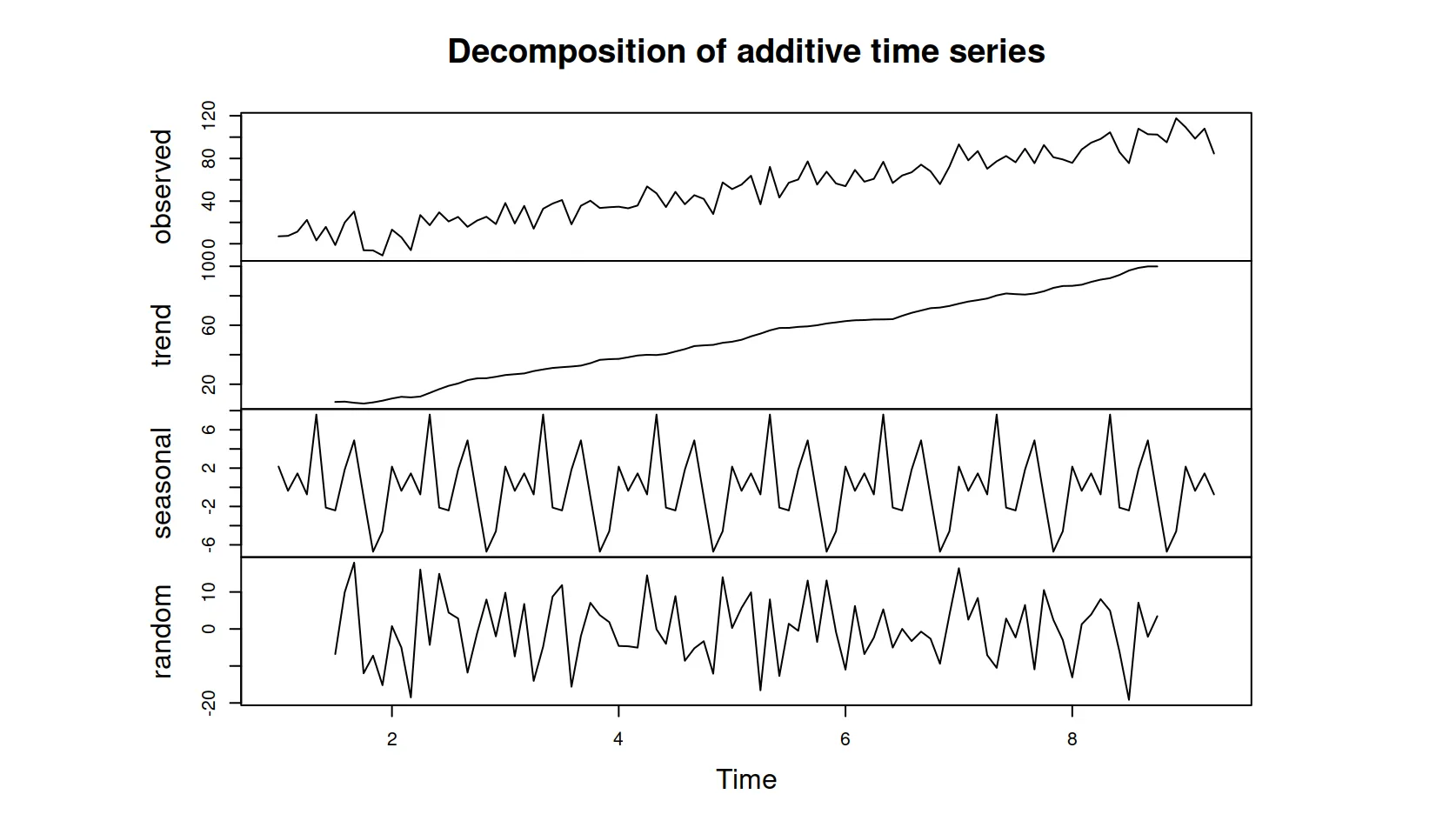
Ogni serie temporale è composta da quattro elementi principali:
Level: il valore medio, la base su cui si costruisce tutto.
Trend: la direzione generale, che può essere in crescita, in calo o stabile.
Seasonality: uno schema che si ripete regolarmente (nota: non si riferisce alle stagioni quali primavera, estate, autunno e inverno).
Noise: il rumore, ovvero ciò che non possiamo spiegare o prevedere.
A volte questi elementi si sovrappongono e rendono difficile interpretare i dati grezzi. Per capire meglio cosa succede, possiamo “scomporre” la serie e isolare ciascun componente: trend, stagionalità e rumore. Questo processo si chiama decomposizione.
La decomposizione non serve solo a vedere più chiaramente le diverse dinamiche: aiuta anche a verificare una proprietà chiamata stazionarietà.
Una serie è stazionaria quando le sue caratteristiche statistiche, come la media o la varianza, rimangono costanti nel tempo.
Molti modelli di previsione, come ARIMA, partono dal presupposto che la serie sia stazionaria.
Se invece i dati mostrano un trend marcato o una stagionalità che cambia nel tempo, possiamo “stabilizzarli” attraverso una trasformazione chiamata differencing, che consiste nel sottrarre a ogni valore quello precedente.
In questo modo rimuoviamo gran parte delle variazioni strutturali e rendiamo la serie più adatta alla modellizzazione.
Non tutte le serie si comportano allo stesso modo.
In una serie additiva, le variazioni (cioè la distanza tra picchi e valli) restano più o meno costanti nel tempo: ad esempio, se ogni dicembre le vendite aumentano di 1.000 €, l’effetto resta fisso.
In una serie moltiplicativa, invece, le variazioni crescono proporzionalmente: se ogni dicembre le vendite aumentano del 10%, l’impatto sarà maggiore man mano che l’azienda cresce.
Un esempio concreto: un negozio online
Immagina di gestire un negozio di e-commerce e di monitorare ogni giorno le vendite.
Il livello medio è di 500 ordini al giorno.
Il trend mostra che le vendite crescono del 5% ogni mese, magari grazie a nuove campagne marketing.
C’è una stagionalità: gli acquisti aumentano nel weekend e rallentano nei giorni feriali.
E poi c’è il rumore: un mercoledì in cui un post virale genera un picco improvviso, o un lunedì in cui un problema tecnico blocca il sito.
Capire questi elementi ti permette di prevedere l’andamento delle vendite, pianificare le scorte e gestire al meglio la strategia pubblicitaria.
Dai modelli più semplici ai più avanzati
Le tecniche di base per fare previsioni si chiamano naïve forecasts.
Sono semplici, ma sorprendentemente efficaci:
Naïve Forecast: ripeti l’ultimo valore osservato.
Mean Forecast: usa la media dei valori precedenti.
Seasonal Naïve: ripeti ciò che è accaduto lo stesso periodo dell’anno precedente.
Modelli più complessi, come ARIMA, Prophet o reti neurali come LSTM, possono catturare schemi più articolati, ma non sempre migliorano realmente le prestazioni. Se un modello semplice funziona bene, è spesso la scelta migliore.
Misurare la bontà di una predizione
Per capire quanto un modello sbaglia, usiamo alcune metriche di accuratezza. Le più comuni sono:
MAE (Mean Absolute Error): misura, in media, di quanto le previsioni si discostano dai valori reali.
RMSE (Root Mean Squared Error): simile al MAE, ma penalizza più severamente gli errori grandi.
MAPE (Mean Absolute Percentage Error): esprime l’errore medio in percentuale rispetto al valore reale.
In generale, punteggi più bassi indicano previsioni migliori, ma il modello “migliore” dipende sempre dal contesto.
Ad esempio, il MAPE può diventare poco affidabile quando i valori reali si avvicinano a zero, mentre l’RMSE può enfatizzare troppo un singolo errore anomalo.
Un buon modello non deve solo “spiegare” bene il passato, ma anche generalizzare su dati che non ha mai visto. Per questo, le prestazioni vengono valutate su un campione di test, cioè dati futuri rispetto al periodo di addestramento. Se un modello semplice, come il Seasonal Naïve, ottiene risultati simili o migliori rispetto a una rete neurale complessa in termini di MAE o RMSE, allora la soluzione più semplice è probabilmente la più efficace e soprattutto più interpretabile.
Le previsioni includono spesso delle fasce ombreggiate intorno alla linea principale, dette intervalli di confidenza. Queste mostrano il margine di incertezza e ci ricordano che non si tratta di indovinare un numero preciso, ma di stimare un intervallo plausibile di valori futuri.
Come per il meteo, è molto più facile prevedere ciò che accadrà domani rispetto a tra tre mesi. Le previsioni a breve termine sono generalmente più affidabili, perché si basano su pattern ancora stabili, mentre quelle a lungo termine diventano più rischiose: i trend possono cambiare, le stagionalità rompersi, e nuovi fattori imprevisti possono emergere.
Gli eventi eccezionali, come la crisi finanziaria del 2008 o la pandemia del 2020, sono esempi di “cigni neri”, situazioni imprevedibili che possono stravolgere i dati storici e rendere i modelli temporaneamente inutili.
In questi casi, decidere se includere o escludere quei periodi nel training non è solo una scelta statistica, ma anche una decisione di business: mantenere quei dati può introdurre distorsioni, ma eliminarli rischia di ignorare lezioni importanti.
In definitiva, una buona previsione non è quella “esatta”, ma quella utilmente precisa: abbastanza affidabile da guidare decisioni concrete, pur riconoscendo che l’incertezza fa sempre parte del futuro.
Pronto a trasformare i tuoi dati in previsioni?
La missione di Dhiria è rendere l’analisi predittiva più accessibile e utile per le aziende che vogliono basare le proprie decisioni sui dati.
Con TIMEX, puoi analizzare e prevedere le tue serie temporali, identificare pattern e trend e ottenere previsioni affidabili senza complessità tecnica.
👉 Scopri come TIMEX può supportare le tue previsioni.
Visita www.dhiria.com o scrivici a info@dhiria.com per una demo personalizzata.




