
If you’ve spent time using LLMs, you’ve probably experimented with their so-called “reasoning” mode. In this setting, the model appears to solve problems using a more structured approach, using what is technically known as chain-of-thought prompting.
But do these models actually reason? Or are we just witnessing surface-level pattern recognition dressed up in more elaborate prompts?
A recent paper from Apple, titled “The Illusion of Thinking,” dives straight into this question. The authors propose a rigorous framework to scientifically evaluate reasoning in LLMs.
The paper’s key contribution is a carefully designed benchmark that evaluates reasoning across problems with tunable complexity, including many that are guaranteed to be out-of-training-distribution. The results are surprising.
One of the insights from The Illusion of Thinking is the fragility of LLM reasoning when exposed to truly novel problems. A significant portion of prior research evaluating LLMs’ reasoning abilities relies on benchmarks like GSM8K, a dataset of grade-school math word problems. These tasks are often used to test arithmetic reasoning and multi-step problem-solving.
However, there’s a catch: many of these benchmark problems (or very close paraphrases) have been seen during the model’s training. This leads to what’s known as data contamination, i.e., a situation where evaluation data overlaps, directly or indirectly, with the model’s training data. As a result, the model’s performance may reflect memorization or shallow pattern matching, rather than genuine reasoning.
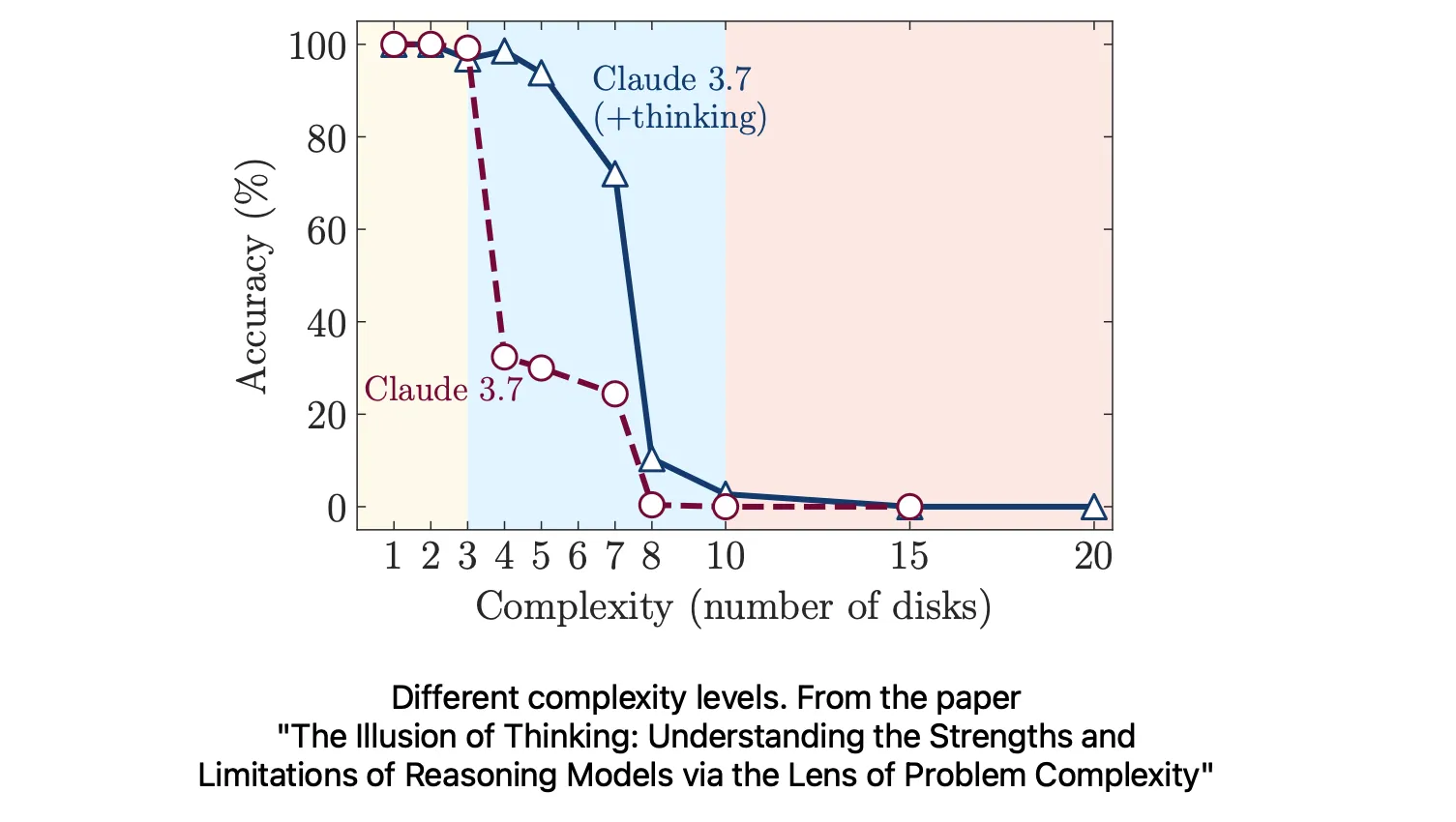
To investigate this, the researchers considered tasks with tunable complexity, like the Tower of Hanoi, where the number of disks can be varied to create simpler or more difficult variations of it. They thus categorized tasks into three tiers:
Low Complexity: Simple problems requiring minimal reasoning steps.
Medium Complexity: Tasks necessitating moderate reasoning and planning.
High Complexity: Challenges demanding extensive, multi-step reasoning.
Their findings revealed that standard LLMs often outperform reasoning-optimized models on low-complexity tasks, as the latter may “overthink,” leading to unnecessary complications. Reasoning LLMs show advantages in medium-complexity scenarios, where structured thinking aids in navigating the problem space, but both model types completely fail in high-complexity tasks. Interestingly, they experience a significant drop in performance despite having sufficient computational resources and token budgets at a certain complexity level.
This performance degradation in high-complexity tasks is particularly intriguing. The models exhibit a “counterintuitive scaling limit,” where their reasoning efforts increase with problem complexity up to a point, then decline, even though they have the capacity to process longer outputs. This suggests that the models may be recognizing the increasing difficulty but lack the mechanisms to effectively manage or strategize through more complex challenges.
The second main contribution of The Illusion of Thinking demonstrates that LLMs often fail to solve problems even when the correct algorithm is explicitly given to them. One might assume that if the model is handed a clear, step-by-step procedure, either in natural language or pseudocode, it should be able to follow it and arrive at the correct answer. After all, executing a known sequence of operations seems like a minimal test for reasoning. But the results tell a different story.
The researchers designed experiments where models were prompted with the full algorithmic description needed to solve a class of problems. Despite this advantage, models frequently deviated from the procedure, skipped steps, or hallucinated intermediate results. In some cases, they abandoned the logic halfway through, even though they still had enough token budget to complete the task.
This failure was not due to lack of capacity or insufficient instruction, it was a limitation in executionfidelity. The models could recite the algorithm, but couldn’t reliably apply it.
Interestingly, the authors note that success in this setting often required agentic LLMs, which are models capable of tool use or code execution. These external systems can offload the structured reasoning task to a reliable backend, such as a Python interpreter. But the paper deliberately isolates this from its scope, focusing instead on what static LLMs can do on their own, without external tools.
The implication is clear: current LLMs are still poor algorithm followers. They don’t reliably bind instructions to actions. Even when the “thinking” is done for them, they may still stumble during execution, another sign that their apparent reasoning often relies more on pattern completion than genuine understanding.
It should be noted that the team led by Bengio had started investigating reasoning LLMs some time ago, with some prior works that paved the way for this last paper.
For instance, a phenomenon they investigated is that changing names, numerical values, or inserting irrelevant details can greatly reduce the effectiveness of reasoning LLMs in solving standard benchmark problems. Surprisingly, even small changes (e.g., swapping “Sophie” with “Mark”) led to substantial accuracy drops. These models, it turns out, can be easily thrown off by superficial edits.
This phenomenon had already been investigated in a previous study by Bengio et al. (GSM-symbolic). In that work, the authors showed that altering entity names or injecting distracting, irrelevant information into math and logic problems could cause LLMs to fail, even when the core reasoning structure remained the same. The key takeaway was that LLMs often succeed not because they understand the problem, but because they recognize a familiar pattern. In other words, they succeed through their “parrot-like” capabilities, not through actual abstraction or reasoning.
Together, these findings challenge the notion that current LLMs possess reasoning skills in any meaningful sense. They may appear to solve complex tasks, but often only because those tasks look familiar, not because the model has truly understood them.

At the International Joint Conference on Neural Networks (IJCNN 2025) in Rome, where I had the chance to attend Samy Bengio’s keynote, he concluded by outlining a promising direction for future work: abstract thinking.
The core idea is simple. During training, annotate input problems with abstract variable markers, such as labeling numbers or entities with symbolic tags (e.g., X, Y, N1) rather than relying on raw natural language descriptions like “Sophie has 5 apples…”. This small tweak encourages models to treat similar problems as instances of the same underlying structure, rather than memorizing surface patterns.
This evolving line of research reminds us that while LLMs may appear clever, true reasoning requires more than just fluent output. It demands structure, generalization, and interpretability.




