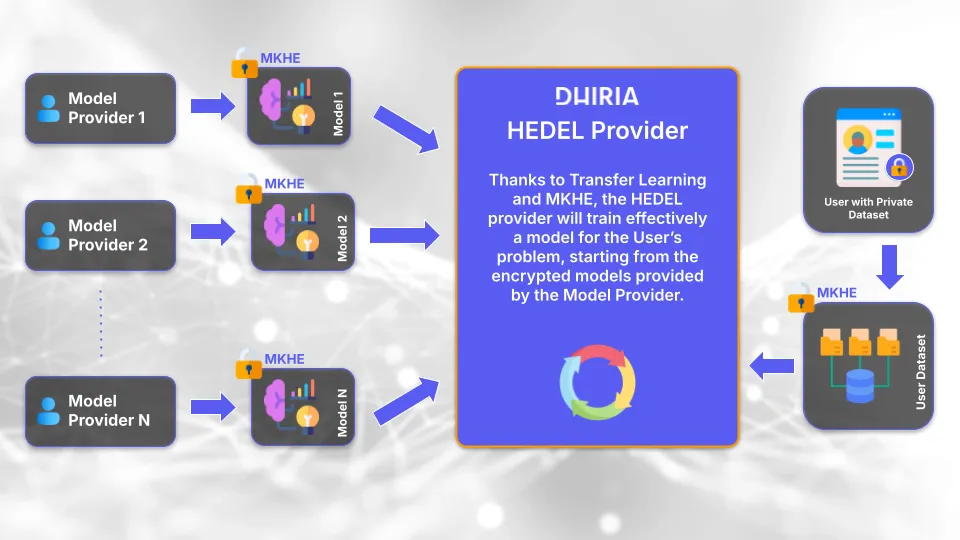
È possibile allenare modelli di machine learning senza avere accesso ai dati su cui fare allenamento?
Sembra un controsenso, eppure grazie ad una tecnica di crittografia chiamata “homomorphic encryption” in Dhiria riusciamo a fare proprio questo.
Normalmente siamo abituati a pensare alla crittografia ed al machine learning come a due mondi molto lontani: nel primo lo scopo è estrarre il maggior numero di informazioni possibili da un set di dati, per poter fare delle previsioni; nel secondo invece abbiamo come obiettivo proprio quello di ridurre al minimo la quantità di informazione che viene esposta da un set di dati, spesso mescolando questi ultimi in maniera irriconoscibile.
Questi due obiettivi sembrano in contrasto tra loro, ma lo sono davvero?
Prima un po’ di crittografia
Anzitutto approfondiamo la definizione abbozzata di crittografia: se è vero che lo scopo è quello di nascondere i dati da occhi indiscreti bisogna specificare un pezzo aggiuntivo, cioè che questa protezione è legata all’utilizzo di una chiave segreta. Chi ha la chiave deve poter accedere ai dati, altrimenti non sarebbe molto utile cifrare qualcosa.
Quindi la crittografia mescola sì i dati in modo “irriconoscibile”, ma solo per chi non possiede la chiave segreta.
Ci sono effettivamente alcuni protocolli crittografici (AES ad esempio) che per criptare i dati inizialmente li “mescolano” in maniera tale da non poterci fare alcuna operazione, o meglio in maniera tale da rendere qualsiasi operazione un'operazione casuale sui dati di partenza. Questi protocolli, se forniti di altri meccanismi di controllo, come una checksum, non solo garantiscono la Confidenzialità ma anche l'Integrità del dato
(CIA triad - https://informationsecurity.wustl.edu/items/confidentiality-integrity-and-availability-the-cia-triad/).
I protocolli di crittografia omomorfica invece mescolano i dati in maniera tale da poter consentire la modifica del dato criptato, pur non conoscendo il dato iniziale.
Questo vuol dire anche che l'integrità del dato è più difficile da garantire, siccome il dato è modificabile in maniera specifica senza distruggere la sua intera struttura. Esistono comunque già tecniche crittografiche in grado di garantire anche l'integrità, come ad esempio le Zero Knowledge Proofs.
Ma quindi come funziona nella pratica?
Il funzionamento della crittografia omomorfica dipende dalla matematica su vettori in spazi a tante dimensioni. Infatti ogni messaggio che vorremmo mandare viene trasformato in un grande vettore.
La fase di cifratura di un dato non fa altro che applicare una trasformazione al vettore, questa stessa trasformazione viene quindi applicata ad ogni dato su cui vogliamo fare ML.
A questo punto tra vettori (dati criptati) possiamo eseguire due operazioni fondamentali: la somma e la moltiplicazione.
Queste due operazioni consentono di eseguire molti modelli di ML usando solo i vettori criptati. Una persona che non ha accesso alla chiave segreta non è in grado di ricavare dai vettori il dato sottostante. Eppure è comunque in grado, grazie alla chiave pubblica, di prendere due vettori e farci delle operazioni.
Proviamo ad utilizzare una semplificazione per capire:
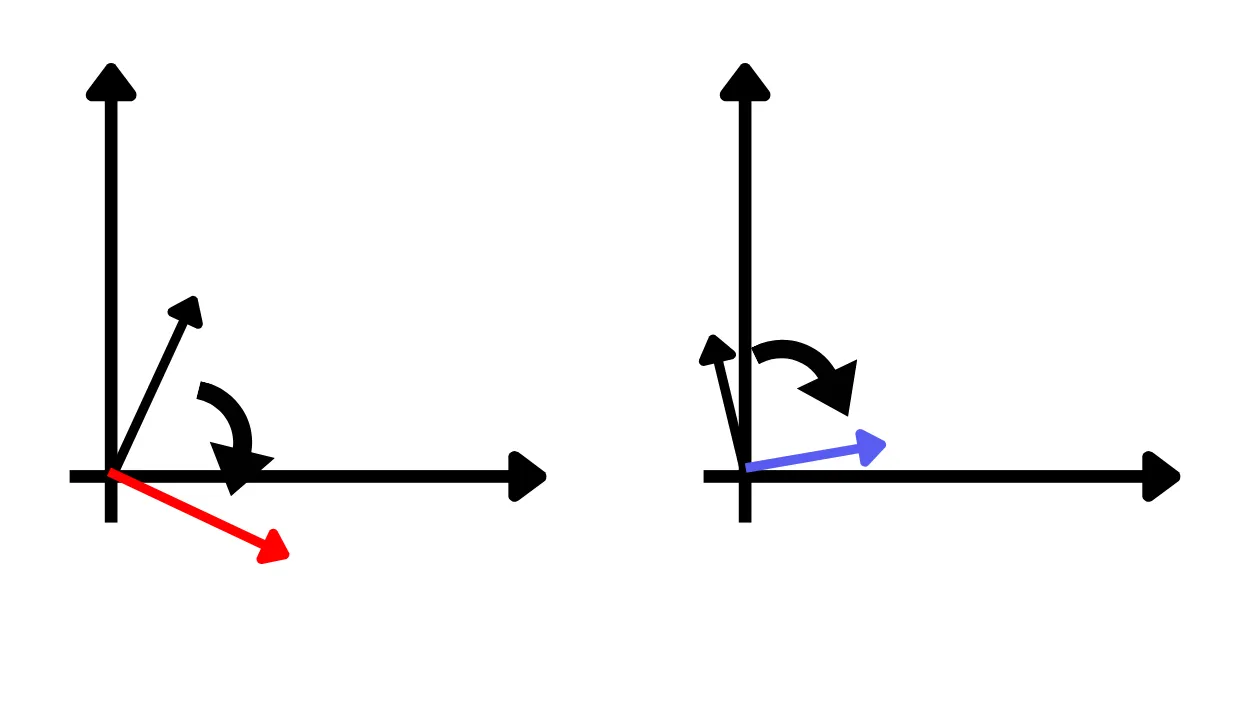
Immaginiamo che l’operazione di crittografia consista semplicemente nella rotazione di un vettore, e che la chiave segreta consista nel valore dell’angolo di rotazione.
Immaginiamo ad esempio di utilizzare come chiave segreta un angolo di 90°.
I passi che dovremo fare saranno i seguenti:
Criptiamo due vettori (in nero) ruotandoli di 90°
Mandiamo i due vettori criptati ad un’altra persona a cui chiediamo di fare la somma
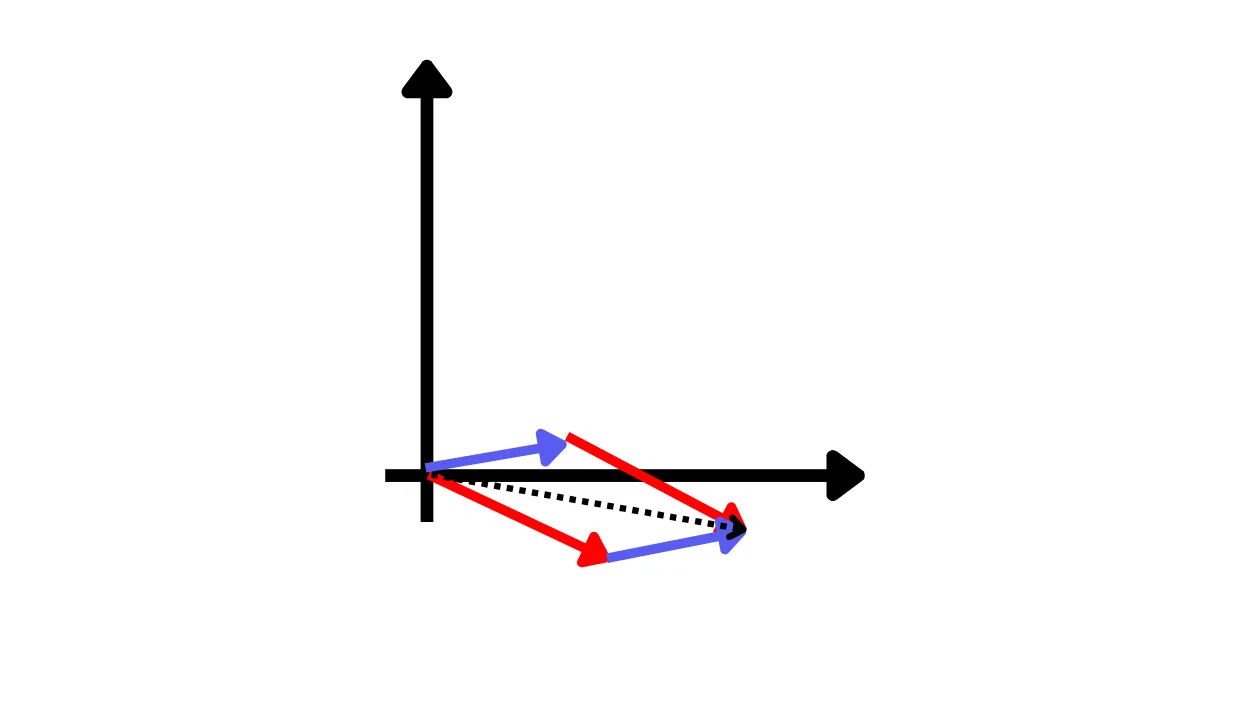
Ci viene restituito il risultato
Ruotiamo in verso opposto di 90° per decrittare (risultato in verde)
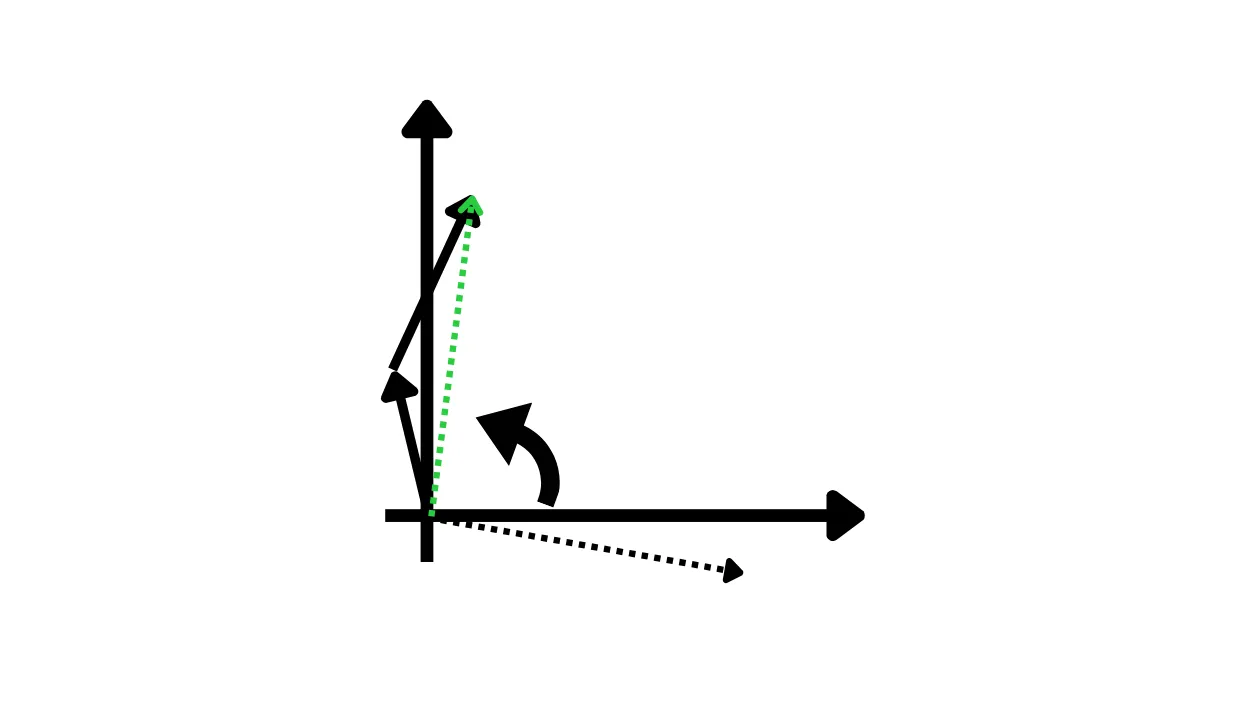
Notiamo come il risultato finale corrisponde al vettore che avremmo calcolato noi se avessimo fatto l’operazione di somma tra i due vettori in chiaro. Trasformazioni di questo tipo, che conservano il legame tra input e output, si chiamano omomorfiche, e da qui viene il nome crittografia omomorfica.
Inoltre la persona con cui abbiamo condiviso i due vettori ruotati non sa di quanto sono stati ruotati e di conseguenza non sa quali sono i nostri due vettori iniziali, eppure è in grado di eseguire una operazione di somma normalmente.
Ora chiaramente questo è un esempio fortemente semplificato, il modellino non è affatto sicuro (rivela l'angolo tra i due vettori e la loro norma), però il concetto di base è fondamentalmente lo stesso con trasformazioni più complicate e più passaggi intermedi.
In particolare i vettori sono in uno spazio da decine di migliaia di dimensioni, in cui una operazione (la decifratura) risulta molto complicata se non si ha accesso alla chiave segreta, mentre altre (come la somma e la moltiplicazione) sono molto semplici da eseguire avendo accesso alla chiave pubblica.
(Per approfondire; https://en.wikipedia.org/wiki/Ring_learning_with_errors)
Grazie alle tecniche di crittografia omomorfica si apre quindi la strada a modelli di machine learning privacy-preserving che possono funzionare su dati sensibili, senza mai esporre informazioni in chiaro.
🔐 Preparati oggi alla sicurezza di domani
Dhiria sviluppa soluzioni di machine learning privacy-preserving integrate con tecniche crittografiche avanzate, come la crittografia omomorfica. Offriamo alle organizzazioni gli strumenti per elaborare dati sensibili in modo sicuro, compliance-ready e a prova di futuro.
👉 Scopri come possiamo aiutarti a proteggere i tuoi dati anche mentre vengono processati!
Contattaci su www.dhiria.com o scrivici a info@dhiria.com per una demo personalizzata.