
Negli ultimi anni il consumo energetico imputabile ai data center è in continuo aumento. Questo è dovuto principalmente all’aumento di domanda di servizi digitali, che porterà secondo alcune stime ad un raddoppio dell’energia consumata dai data center entro il 2030 (3% della domanda di energia globale, confrontabile con il consumo energetico del Giappone) (fonte).
Una fetta molto importante dei consumi è dovuta al raffreddamento richiesto dai grandi centri di calcolo, e qui sorge una domanda forse apparentemente banale, perché i computer scaldano così tanto?
Negli anni ‘60 un fisico che lavorava in IBM, Rolf Landauer, si è posto proprio questa domanda, ed è giunto ad una conclusione interessante (fonte): Il calore inevitabilmente disperso dai computer per fare un calcolo è dovuto alla perdita di informazione che avviene all’interno dei transistor. In altre parole anche costruendo un computer efficientissimo, costruito con superconduttori (che non si scaldano con il passare della corrente), questo comunque emetterebbe calore a causa della distruzione di informazione.
Facendo un esempio: Una delle operazioni basilari che avvengono all’interno di un microprocessore è l’operazione binaria AND, che riceve due bit in input e restituisce un bit in output, il bit in output è 1 solo se entrambe i bit di input sono 1 e 0 altrimenti.
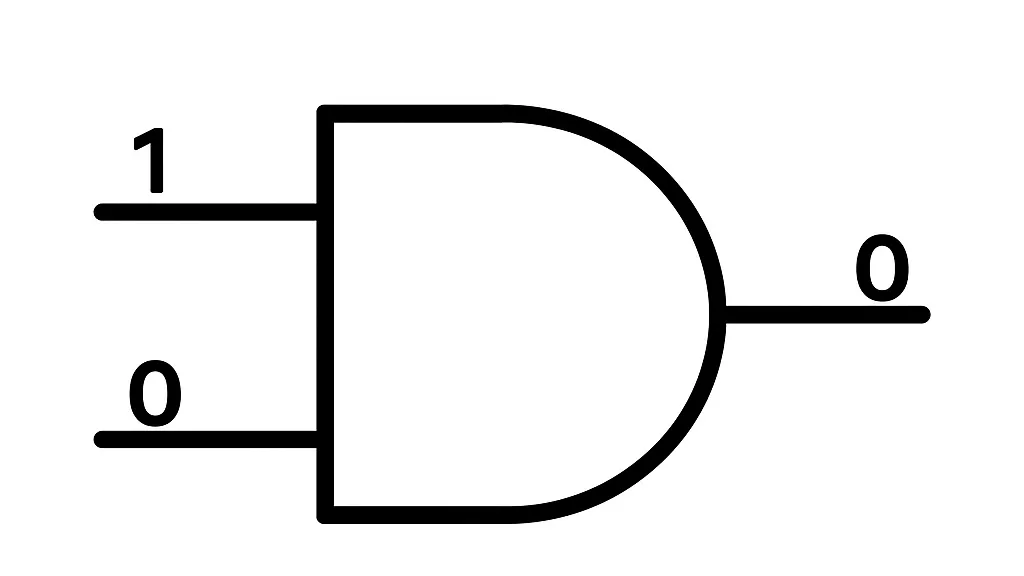
Questa operazione cancella l'informazione, perché produce un solo bit partendo da due e non è quindi reversibile: se infatti sapessimo che il risultato di un AND è 0 non saremmo in grado di riprodurre i due bit iniziali.
Landauer si chiese quindi se fosse possibile realizzare calcoli senza però distruggere informazione, così da ridurre quasi fino a zero l’energia dispersa durante una operazione.
Un primo approccio
Per dimostrare che fosse possibile realizzare un computer “normale” usando operazioni reversibile Landauer propose un prototipo molto semplice: basterebbe salvare l’informazione aggiuntiva necessaria a ricostruire i bit iniziali da qualche parte così da non distruggerla e per il resto i calcoli sarebbero identici a quelli effettuati da un computer tradizionale.
Esempi di gate reversibili sono il Toffoli gate ed il Friedkin gate con tre ingressi e tre uscite.
Questo approccio però presentava ancora un problema: Prima o poi tutti i bit messi da parte occuperebbero troppo spazio e dovremmo comunque cancellare dell’informazione riproponendo il problema iniziale.
Fu uno studente di Landauer negli anni ‘70 a proporre una soluzione: anziché salvare tutti gli stati intermedi di un calcolo è sufficiente invertire ogni operazione dopo aver copiato il risultato, per garantire di non cancellare informazione. In sostanza dopo aver ottenuto il risultato di un gate dovremmo copiarlo e poi ritornare ai bit di input dai bit di output.
L’evoluzione di una idea
Dopo le prime proposte teoriche si è cercato per molto tempo di costruire gate reversibili con diverse tecnologie: partendo dai CMOS utilizzati nei processori, con piccolissimi gate meccanici o con tecnologie ancora più sofisticate.
Alla fine ci si è resi conto che la realizzazione ingegneristica di un processore reversibile è molto dispendiosa e richiede processi di fabbricazione che sono da studiare da zero.
Una delle caratteristiche principali dei gate reversibili è quella di essere più lenti rispetto ai gate tradizionali, e la soluzione sarebbe quella di realizzare processori che stratificano gate reversibili su tanti livelli per colmare il gap di performance. I moderni processi di produzione dei microprocessori però rendono ancora molto difficile la costruzione di strutture in 3D e quindi vanno ingegnerizzati processi nuovi.
Dove siamo arrivati oggi?
Nonostante il progresso notevole che hanno visto le tecniche di fabbricazione dei processori standard la realizzazione di processori reversibili sembra ancora lontana.
Di anno in anno però ci stiamo avvicinando alle massime possibili performance ottenibili da un processore classico, e il problema del calore prodotto è sempre più rilevante nel processo di design di un processore.
Il reversible computing consentirebbe di portare molto vicino a zero gli sprechi di energia dovuti al calcolo.
Recentemente è nata anche una startup che si prefigge come obiettivo dimostrare la possibilità di realizzazione di un processore reversibile, per spingere anche i grandi player dell’industria dei semiconduttori a investire in questa direzione. Siccome i processi di produzione dei moderni processori sarebbero da ripensare da zero, c’è poco interesse da parte delle grandi aziende di investire nella direzione del computing reversibile almeno fino a che non sia più possibile migliorare le architetture attuali.
Se oggi il reversible computing è una scommessa per pochi pionieri, domani potrebbe essere la chiave per utilizzare strumenti di intelligenza artificiale sofisticati consumando pochissima energia.
Vuoi scoprire come costruire un futuro digitale più sostenibile e intelligente?
In Dhiria esploriamo ogni giorno tecnologie per efficientare le infrastrutture e proteggere la privacy degli utenti. Contattaci su www.dhiria.com o scrivici a info@dhiria.com per una demo personalizzata.


