
L’Intelligenza Artificiale (IA) sta cambiando profondamente il nostro modo di vivere, lavorare e prendere decisioni, alimentando tecnologie che un tempo appartenevano alla fantascienza. Dalla diagnostica medica personalizzata ai veicoli autonomi e ai sistemi di raccomandazione, l’IA guida oggi la ricerca in quasi ogni settore.
Eppure, dietro ogni sistema intelligente si cela la necessità di una mole massiva di dati. Per raggiungere accuratezza e generalizzazione tra utenti, popolazioni o compiti, i modelli richiedono enormi volumi di dati diversi e rappresentativi, la maggior parte dei quali è sensibile e fortemente regolamentata. Centralizzare queste informazioni non è solo poco pratico, ma anche eticamente scorretto e spesso vietato da normative come il GDPR e l’HIPAA.
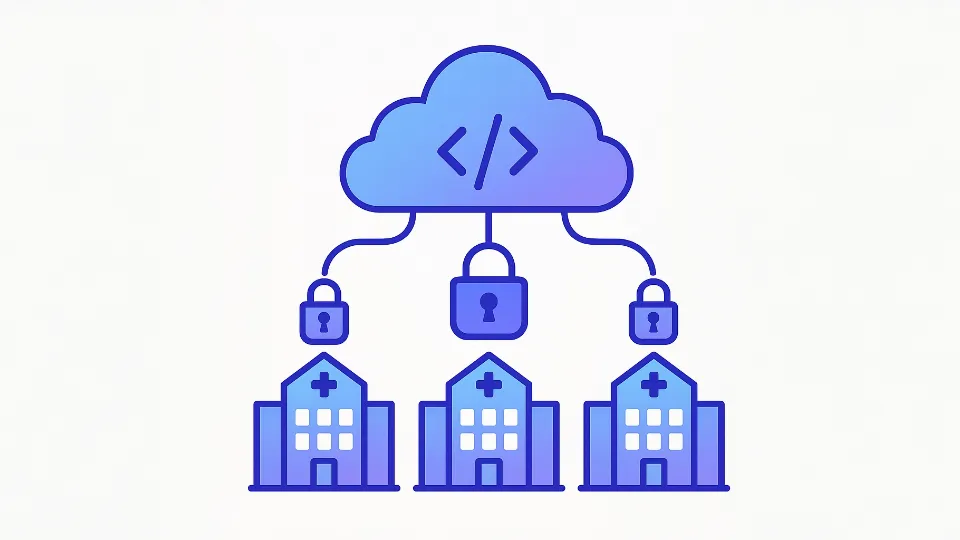
È qui che entra in gioco il Federated Learning (FL), che consente l’addestramento di modelli di IA attraverso la collaborazione di dispositivi o silos distribuiti. In questo modo, ospedali e centri di ricerca, ad esempio, possono allenare insieme modelli diagnostici per riconoscere malattie rare, contribuendo con informazioni preziose senza mai condividere direttamente le cartelle cliniche dei pazienti.
Ma, per quanto promettente, il FL non è intrinsecamente privacy-preserving.
Una risposta promettente, ma incompleta
Nonostante la sua natura decentralizzata, FL rivela più di quanto sembri. Gli aggiornamenti del modello condivisi durante l’addestramento non sono semplici numeri: possono infatti trapelare informazioni sensibili.
Un attacker potrebbe ricostruire parte dei dati originali, come immagini o cartelle cliniche, determinare se i dati di una specifica persona sono stati utilizzati durante l’addestramento, o addirittura risalire a pattern nascosti o caratteristiche sensibili che non dovevano essere condivisi. Il problema risiede negli stessi aggiornamenti: conservano tracce dei dati che li hanno generati, rendendo il FL da solo ben lontano dall’essere realmente privacy-preserving.
La parte mancante
Consentendo il calcolo direttamente su dati cifrati, la Crittografia Omomorfica (Homomorphic Encryption, HE) riempie la lacuna lasciata dal FL, trasformando la protezione dei dati da promessa a realtà. Gradienti e aggiornamenti di modello possono essere elaborati su dispositivi, silos e server senza mai rivelare i loro valori originali.
Di conseguenza, chi non possiede la chiave di decrittazione, che si tratti di un intermediario curioso o di un server compromesso, non può ottenere alcuna informazione sensibile. Anche in caso di violazione, nessun dato significativo può essere estratto senza la chiave segreta.
L’HE, quindi, ridefinisce completamente il modello di fiducia del FL. Anziché inviare aggiornamenti in chiaro, ogni client cifra i propri gradienti prima di trasmetterli al server. Quest’ultimo, incapace di decifrarli, li aggrega, senza mai poter accedere ai contenuti. Una volta completata l’aggregazione, restituisce il risultato cifrato ai client, che lo decifrano localmente e proseguono con l’addestramento del modello. In nessun momento qualcuno diverso dal proprietario dei dati ha accesso alle informazioni sottostanti.
A seconda dello schema di cifratura, ciò può avvenire in due modi. Nel modello single-key, tutti i client condividono la stessa chiave di cifratura, permettendo al server di aggregare facilmente gli aggiornamenti e restituire un unico ciphertext che qualsiasi client può decifrare. Questo approccio è particolarmente adatto a contesti in cui tutte le fonti di dati appartengono a un’unica entità fidata, come nel caso di dispositivi IoT operanti all’interno della stessa organizzazione e sotto un’unica infrastruttura di sicurezza. Al contrario, nel modello multi-key, ogni client utilizza una chiave diversa. Questo schema è ideale per collaborazioni tra entità indipendenti, dove è essenziale garantire un forte isolamento dei dati, come ospedali che addestrano insieme un modello diagnostico senza mai scambiarsi i dati dei pazienti, o banche che collaborano per rilevare frodi mantenendo riservate le proprie informazioni. Sebbene più complesso dal punto di vista crittografico, questo approccio assicura un livello di privacy molto più elevato, fondamentale in contesti sensibili e altamente distribuiti.
In entrambi i casi, la privacy non è affidata a un’autorità centrale, ma è garantita dal design stesso del sistema.
Non solo decentralizzato, ma anche Privacy-Preserving
Il FL ha rappresentato un passo importante verso la decentralizzazione dell’IA, ma decentralizzare non significa automaticamente proteggere la privacy. Senza misure di sicurezza forti, informazioni sensibili possono ancora trapelare proprio attraverso quegli aggiornamenti pensati per mantenere i dati locali. L’HE cambia radicalmente le regole del gioco. Non si limita a migliorare il FL: lo completa, trasformandolo nel framework privacy-preserving che avrebbe sempre dovuto essere. Combinare FL e HE non è più un'opzione, ma una necessità per costruire sistemi di IA potenti e affidabili.
In DHIRIA stiamo lavorando attivamente in questa direzione, portando avanti la ricerca per rendere il FL privacy-preserving non solo come possibilità, ma come realtà concreta, sicura e pronta per le sfide del mondo reale.




